
CNN(Convolutional Neural Network)
CNN(Convolutional Neural Network)은 Convolution(합성곱) 연산을 활용해서 데이터의 모양 정보를 추출하는 방법과
추출된 정보를 학습하는 딥러닝 알고리즘이다.
특히 데이터의 임의 지점의 정보와 그 주변 정보 간 연관성을 이해할 수 있어서 Computer Vision 분야에서 큰 성과를 이루었다.
본 포스트에서는 CNN 알고리즘이 이미지 데이터를 받아서 계산하는 방법과 그 과정을 쉽게 풀어보고 CNN을 직관적으로 이해해 본다.
알고리즘을 혼자 공부하고 이해한 것에 대한 내용이므로 부정확하거나 사실과 다를 수 있습니다.
CNN 구조
아래는 CNN을 이용한 Image Classification 알고리즘이며 CNN을 상상할 때 가장 보편적으로 떠올리는 구조이다.
그림에서 생략됐지만 Filter가 Conv1 Layer의 앞에 위치해있는 것처럼 Conv2, Conv3 Layer의 앞에도 위치해 있다.
이 포스트는 아래 Image Classification 알고리즘 구조의 구성 요소를 살펴보면서 CNN을 설명한다.
특별 출연한 귀여운 고양이의 이름은 까무입니다 😆
용어
본격적인 설명에 앞서 CNN에서 사용하는 주요 용어를 나열해본다.
- Padding
효율적인 Convolution 연산을 위해 이미지에 여백을 추가하는 작업. - Filter
Convolution 연산의 2개 피연산자 중 이미지를 제외한 다른 하나. CNN 학습을 통해 생성됨. - Convolution
합성곱이라고 하며 데이터의 모양 정보를 추출하는 수학적 기법. CNN 알고리즘에서는 수학적 Convolution과 유사한 아이디어를 학습에 활용. - Stride
Convolution 연산의 피연산자를 이동시키는 작업. - Feature Map
Convolution 연산의 결과물. - Pooling
Convolution 연산 결과를 Reducing 하는 작업. - Channel
이미지 데이터를 여러 겹으로 표현할때 그 레이어를 표현. (예. RGB 컬러 이미지: 3 Channel) - Kernel
Filter와 같은 역할을 하기 때문에 같은 것을 뜻한다고 많이 표현되나, 엄밀히 따지면 Filter 보다 세밀한 단위이다.
수학적 Convolution
수학 분야에서의 Convolution(합성곱)을 먼저 살펴보자. Convolutional Neural Network 라는 명칭에 떡하니 나오는 것인 만큼 당연히 CNN 알고리즘과 매우 밀접하게 관련돼 있지만, 해당 섹션에서 Convolution에 대한 수학적 이해가 CNN의 연산 방법을 파악하는데 필수적인 것은 아니다. 그렇지만 CNN 알고리즘의 핵심 아이디어인 만큼 알고가는게 좋을 것 같다. 그럼에도 시간이 부족하다면 이 섹션은 넘어가도 좋다.
위키피디아의 Convolution 페이지에서 문단 제일 처음에 Convolution을 아래와 같이 소개하고 있다.
In mathematics (in particular, functional analysis), convolution is a mathematical operation on two functions (\(f\) and \(g\)) that produces a third function (\(f*g\)) that expresses how the shape of one is modified by the other.
해석하면,
‘수학에서, Convolution은 2개 함수(\(f\)와 \(g\))에 대한 수학적 연산인데 연산을 통해 하나의 함수(\(f\))가 다른 함수(\(g\))에 의해 변형되는 모양을 표현하는 세번째 함수(\(f*g\))를 만든다.’
라는 의미이다. 물론 나의 뇌는 맑고 깨끗하므로 잘 이해되지 않는다. ^^
아무튼 Convolution은 수학식으로 아래와 같다.
이게 대충 뭐냐면 \(t\) 값을 변화시켜 가면서 함수 \(g\)가 가질 수 있는 모든 값과 함수 \(f\)가 가질 수 있는 모든 값을 곱한다는 뜻이다.
\(t\) 값의 변화란 아래 움짤처럼 함수 \(g\)가 미끄러지게 하는 역할을 한다. 또 함수 \(f\)와 \(g\) 모두 동일한 정의역 \(\tau\)를 갖는다. 따라서 함수 \(g\)는 함수 \(f\)와 \(t\) 만큼의 거리 차이를 갖는다고 할 수 있다.
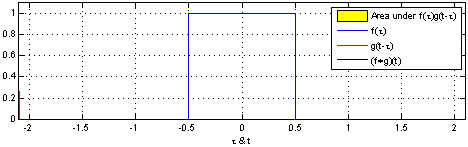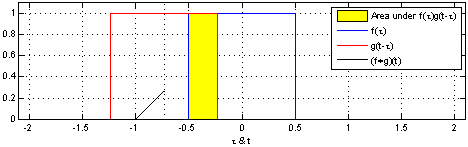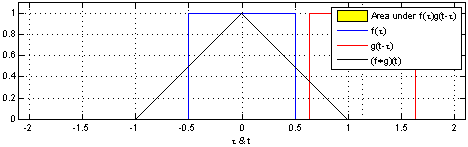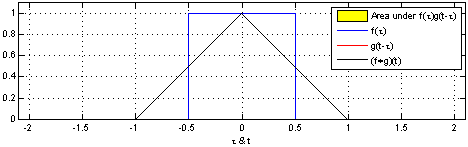
위키피디아 Convolution 페이지의 Visual explanations of convolution 참조
이때 Convolution은
‘\(t\)가 특정한 값일 때,
함수 \(g\)에 가능한 모든 \(\tau-t\)를 대입해서 나온 값 \(g(t-\tau)\)들과
함수 \(f\)에 가능한 모든 \(\tau\)를 대입해서 나온 값 \(f(\tau)\)들 간의 곱셈 연산’을 하는 것을 의미한다.
예를 들어, 가능한 \(\tau\)가 0, 0.5이면 함수 \(f\)와 \(g\)의 Convolution은 \(f(0)g(t-0)+f(0.5)g(t-0.5)\)가 된다.
그다음 \(t\)가 무수히 많을 때, 가능한 모든 \(t\)에 대해 Convolution을 하면 위 움짤 처럼 함수 \(g\)가 미끄러지듯 움직이며 곱셈을 반복한다고 볼 수 있다.
또한 Convolution을 하는 목적은 모든 \(t\)에 대해 Convolution 연산을 함으로써 빨강 함수 \(g\)와 파랑 함수 \(f\) 두 함수를 합성하고 검은색 함수 \(f*g(t)\)를 만드는 것이다.
\(f*g\) 함수는 함수 \(f\)를 함수 \(g\)가 스캔하며(미끄러지며) 지나가고 그에따라 스캔 결과를 반환하는 모양새이다.
이때 스캔하려는 함수 \(g\)를 사전에 알고 있는 함수로 고정한다면, \(f\)를 스캔하면서 나온 결과를 보고 어떤 해석을 도출 할 수 있을 것이다.
이런 특성을 활용해서 CNN의 아이디어인 ‘이미지 데이터(함수 \(f\))를 딥러닝을 통해 학습되는 어떤 Filter(함수 \(g\))로 스캔(Convolution)하여 머신이 이해 할 수 있는 이미지에 대한 모양 해석 정보를 얻는다.’가 나온다.
Convolution in CNN
수학적 Convolution과 비교하면 CNN의 Convolution은 특정 이미지들이 가진 데이터 또는 분포(함수 \(f\))와 CNN 알고리즘이 학습 과정에서 얻는 가중치(함수 \(g\), Filter)간의 합성곱 연산(\(f*g\))이라고 할 수 있다.
예시 이미지
먼저 아래와 같은 이미지 데이터가 있다고 하자. 하나의 칸은 하나의 픽셀을 의미한다.
사실 진짜 이미지 데이터는 픽셀마다 RGB(Red, Green,
Blue) 세가지 색 속성값의 혼합으로 표현될 수 있고 R, G, B 각 값의 범위는
최대값(255), 최소값(0)이며 값의 크기가 갖는 의미(클수록 밝고 작을수록 어두움)가 분명하다.
그래서 오히려 실제 RGB 이미지 데이터는 컴퓨터가 이해하기 쉽다는 점을 기억해두자.
다만 여기서는 쉬운 설명을 위해 그러한 점을 무시할 것이다.
수학적 Convolution에 대한 설명 섹션으로 보면 위 이미지 데이터가 함수 \(f\)에 해당한다.
아래서부터는 Convolution을 Conv로 줄여서 표현하기도 한다.
Padding
최초의 Conv 연산 전에 이미지는 Padding이라는 단계를 거친다. Padding이란 이미지 테두리 바깥에 여백을 추가하는 것을 말하는데 Convolution 연산 결과의 크기가 이미지 크기 보다 작아지지 않도록 하고, 정보가 손실되는 것을 방지하기 위해 사용한다.
아래 그림은 3x3 사이즈의 이미지를 0 값을 가지는 공백 픽셀이 둘러싼 모양을 표현한다. 이렇게 특정한 값을 가지는 공백 픽셀로 이미지를 둘러싸는 것이 Padding 방법이다.
Padding과 Convolution 간 관련성
아래 Padding 된 이미지에서 굵은 테두리로 감싼 영역이 최초의 Convolution 연산에 사용되는 값의 범위이다.
아래 예시처럼, Convolution에서 이 영역은 크기를 유지한채 이미지를 모두 훝을 때까지 위치를 바꿔가며 연산에 사용된다.
이때 이 영역을 잡는 조건이 있다.
‘가로, 세로의 길이가 같은 정사각형이며 한 변의 길이는 1 보다 크도록 한다.’는 것이다.
그리고 균형을 위해 홀수로 하는 것이 좋다. (일반적으로 홀수로 정의한다)
바로 이 조건 때문에 Padding이 필요해진다. 아래 그림에서 곱셈 영역의 크기를 가로x세로=3x3 로 할 때, 조건을 만족하고 Padding을 제외한 이미지의 가장 바깥쪽 픽셀(진한 노랑)이 영역의 가운데로 오도록 영역을 그리면 Convolution 연산의 결과가 이미지의 크기와 같아지는데, 그렇게 하려면 이미지 바깥에 1칸의 공간이 더 필요해진다. 그래서 그 공간을 만들기 위해 Padding을 하는 것이다.
따라서 곱셈 영역의 크기를 가로x세로=5x5로 한다면, 조건을 만족시키기위해 Padding 영역을 1칸이 아니라 2칸으로 잡게된다.
Zero Padding
Padding을 하는 방법에도 여러 방법이 있는데 그 중, Padding 영역의 픽셀 값을 0으로 채우는 것을 Zero Padding 이라고 부르며 여러 방식의 Padding 중 Zero Padding을 사용하는 것이 일반적이다.
0 이라는 숫자는 다른 수를 곱하거나 나누었을 때 그 결과 또한 0 이므로 ‘아무것도 없음’, ‘변함 없음’을 표현하는데 유용하다.
따라서 규모가 큰 CNN은 Convolution 연산에서 곱셈이 아주 많이 반복해서 이뤄지고 복잡해 지는데,
Padding 영역의 값이 원래 이미지 데이터에 있던 정보가 아님을 확실히 표현할 수 있다.
또한 다른 분야와 달리 Computer Vision 분야는 이미지를 RGB로 표현할 때 가능한 가장 작은 값이 0 이므로
시각적인 의미를 부여할 수 있다.
Filter
Filter는 CNN 알고리즘의 핵심 아이디어이다. CNN은 Filter를 통해 이미지의 모양 정보를 추출한다. 또한 Deep Learning 모델의 학습 가능한 가중치 매트릭스이다.
그리고 Padding에서 얘기했던 Padding과 Convolution 간 관련성에서 곱셈의 피연산자 중 하나이다. 즉, 이미지 데이터의 영역과 곱해지는 대상이다.
아래 그림은 Filter 예시이다. 각 값은 이미지의 픽셀 값과 달리 상한, 하한이 특별히 정해져있진 않다.
Filter의 사이즈는 Padding과 Convolution 간 관련성에서 언급한 영역의 크기와 같다. 영역의 크기를 정의하기 위한 조건에서 영역의 크기란 바로 Filter 크기를 의미하는 것이다.
즉, Filter의 크기가 가로x세로=3x3 이면 Padding은 1칸이 되고 Filter의 크기가 5x5 이면 Padding은 2칸이 된다.
Filter의 각 칸의 값들은 Convolution 연산에서 이미지의 영역의 픽셀 값들과 1:1로 곱해진다.
CNN 알고리즘의 핵심 아이디어인 Filter가 더욱 특이한 이유는
Filter가 이미지를 각각의 픽셀 단위로 보는것이 아니고 픽셀의 그 주변 픽셀을 함께 고려한다는 점과,
Filter 가중치의 값이 고정돼 있지 않고 이미지 종류에 따라 학습을 통해 적절한 형태로 변환 될 수 있다는 점이다.
쉽게 말해서 CNN 알고리즘은 Filter라는 탐지기로 이미지를 스캔해서 목적에 맞는 정보를 추출하는 과정이며 CNN 알고리즘 학습이란 목적 달성률을 높이는데 더 효과적인 탐지기(Filter)를 만들어가는 과정이라고 할 수 있다.
수학적 Convolution에 대한 설명은 가장 처음 섹션 Convolution을 참고하자.
CNN 알고리즘 학습 초기에 이 가중치는 랜덤하게 초기화 되어 들어간다(특정 패턴을 가지고 초기화 할 수도 있음).
Convolution
Convolution 연산 방법
다음으로 아래는 CNN 알고리즘 Convolution의 첫번째 스텝을 보여주는 그림이다.
방정식 왼쪽 항의 노란 매트릭스는 Padding된 이미지 데이터이고 중간의 파란 매트릭스는 Filter이자 CNN 알고리즘이 학습하면서 얻는 가중치 매트릭스이다. 그리고 오른쪽 항의 초록 매트릭스는 곱셈 결과이고 Feature Map이라고 부른다.
이제 Padding된 이미지 데이터에서 굵은 테두리로 표시한 영역과 Filter의 값을 같은 위치에 1:1 대응하는 값들끼리 곱하여 모두 더한다.
다시 말해서 Padding된 이미지의 좌표 (1,1)의 값은 Filter의 좌표 (1,1)의 값과 곱하고 (1,2)는 (1,2)와 곱하는 식으로 같은 좌표에 해당하는 값들끼리 곱한 후 그 결과들을 모두 더한다.
위 영역을 예로들면, 영역의 첫번째 행부터 순서대로
가 된다.
이처럼 Filter를 사용하면 이미지의 1개 픽셀만 보는 것이 아닌 주변의 픽셀을 함께 고려하므로 특정 픽셀과 그 주변 픽셀 간 연관성을 이해할 수 있게 된다.
Convolution 연산 반복
위 섹션 Convolution 연산 방법에서 이미지와 Filter 간 곱연산을 했다. 이제 아래 그림과 같이 영역이 이미지의 끝에 도달할 때 까지 한 칸 씩 Shift하면서 같은 곱연산을 반복한다.
이때 Shift 작업을 Stride 라고 하며, 1칸 씩 이동하는 것을 1 stride 라고 한다.
stride의 크기는 머신 제작자의 의도에 따라 원하는 값을 사용 할 수 있지만 일반적으로는 1을 사용한다.
stride 1이 일반적인 이유는 이미지 정보를 정밀하게 스캔하는 효과를 내기 때문이라고 유추 된다.
여기서 Padding의 효과를 명확히 확인해 볼 수 있다.
오른쪽의 초록색 매트릭스가 Convolution의 결과인데 Padding 덕분에 그 크기가 가로x세로=3x3로 처음의 Image 사이즈(Padding 제외)와 동일한 것을 볼 수 있다.
만약 Convolution을 Padding 없이 진행했다면 아래와 같이 Convolution의 결과가 원래 이미지의 크기보다 작아지게 되었을 것이다.
Feature Map
섹션 Convolution 연산 반복에서 설명한 ‘Stride 하며 Convolution 연산을 수행한 결과’를 Feature Map이라고 부른다.
이 Feature Map에는 이미지를 스캔해서 얻은 데이터의 모양 정보가 담기게 된다.
아래 그림은 Filter의 종류에 따라 어떤 Feature Map이 얻어지는지 보여주는 이미지 처리 방법 예이다.
아래 예에서는 CNN 기법이 아닌 기존의 수학적 이미지 처리 방법들에 대해 설명하고 있다.
위키피디아 Kernel_(image_processing) 페이지 참조
Channel & Kernel
이번엔 이미지가 컬러일 경우에 대해 알아보자.

위키피디아 MNIST_database 페이지 참조
지금까지 1장의 Filter로 Feature Map을 생성하는 Convolution 연산에 관해 살펴봤다. 1장의 Filter로 이미지를 스캔할 수 있다는 말은 이미지가 각 픽셀에 명암만을 담고있는 흑백 이미지라는 말이다.
앞서 얘기한대로 컴퓨터에서 컬러 이미지를 표현할 때는 주로 RGB 3개의 색 속성값을 이용한다(다른 표현 방법들도 있음).
RGB란 각각 Red Channel, Green Channel, Blue Channel로 구성된 3개 Channel을 의미하며 Channel 마다 0~255 범위의 값을 갖고 있다. 그리고 픽셀 마다 3개 Channel의 색 혼합으로 여러가지 색상을 만들어낸다.
그다음 Convolution 연산을 위해 이미지에 Filter를 대응시키는데, 이전 설명에서 Filter가 1장이었던 것과 달리 이번에는 3개 Layer로 구성된 Filter를 사용하며 이미지의 3개 Channel과 Filter의 3개 Layer를 1:1 대응시킨다.
이때 Filter를 구성하는 여러 겹의 Layer를 Kernel이라고 부른다.
인터넷에서 CNN에 대한 설명들을 보면 Filter와 Kernel을 같은 것으로 취급하곤 하는데
여러개의 Kernel이 모여 1개의 Filter를 만든다는 점에서 두 용어의 개념에 차이가 있다.
Red Channel과 빨강색 Kernel의 Convolution 결과, Green Channel과 초록색 Kernel의 Convolution 결과, Blue Channel과 파랑색 Kernel의 Convolution 결과 총 3개의 결과가 나오면 이것이 3개의 Feature Map이 되는 것이 아니고 3개의 결과를 더하여 합친 후 하나의 Feature Map으로 만든다.
3개 결과를 더하여 합칠 때는 같은 자리의 값들끼리 더한다. 예를 들어, 하나의 Convolution 결과 매트릭스에서 좌표 (1,1) 자리의 값은 다른 모든 Convolution 결과 매트릭스에서 같은 좌표 (1,1) 자리의 값과 더하여 Feature Map 좌표 (1,1) 자리의 값이 된다.
이런 방식으로 1개의 Filter로 Convolution 하면 Filter가 여러개의 Kernel로 구성되어 있더라도 항상 1개의 Feature Map이 생성되도록 한다.
Multiple Filter
아래는 처음에 보였던 CNN의 기본 구조이다. 각 Layer 별로 Label을 달아 놨는데 그 중 Conv1, Conv2, Conv3, Layer는
Filter로 Convolution 연산을 해서 생성한 것이다.
그런데 이 CNN 구조 그림에서 특이한 점이 있는데, Convolution 연산의 결과가 1장의 2D 매트릭스가 아닌 3D 박스로 표현되어 있다. 그리고 Convolution Layer를 거듭할수록 그 두께가 두꺼워진다.
지금까지는 아래와 같이 1개 Filter가 몇개의 Kernel을 가졌는지에 상관없이 Convolution 연산 결과로 항상 1장의 Feature Map을 생성했다.
이번에는 N개의 Filter를 이미지에 Convolution해서 N장의 Feature Map을 만든다. 그래서 CNN 구조 그림에서 처럼 Convolution의 결과가 여러겹의 Feature Map이 모인 3D 박스로 표현된다.
이처럼 여러개의 Filter를 사용하는 것은 하나의 이미지를 여러 관점에서 스캔해서 다양한 해석을 내놓는다는 의미이므로 CNN Image Classification 목적 달성률을 높이는데 도움이 될 것이라고 생각해 볼 수 있다.
Channel & Kernel 섹션에서 Kernel이 여러개인 Filter라도 1개의 Feature Map을 얻는 것과 달리, 이번 섹션에서는 Filter가 여러개이므로 여러개의 Feature Map을 얻는다는 점을 알아두자.
Multi Layered Convolution
구조 그림에서는 생략됐지만 Filter가 Conv1 Layer의 앞에 위치해있는 것처럼 Conv2, Conv3 Layer의 앞에도 위치해 있다.
지금까지 1장의 이미지와 1개 Kernel을 가진 1개 Filter 간 Convolution,
1장의 이미지와 여러개의 Kernel을 가진 1개 Filter 간 Convolution,
1장의 이미지와 여러개의 Filter 간 Convolution을 보았다.
이번에는 이미지아의 Convolution이 아닌, 여러장의 Feature Map과 Filter 간 Convolution을 살펴본다. 이 경우는 Convolution 결과에 또다시 Convolution을 수행하는 것으로 Multi Layered CNN이라 할 수 있다. 이때 필요한 모든 것은 이미 앞에서 설명이 끝났으므로 금방 읽고 넘어갈 수 있을 것이다.
아래의 Conv1 Layer는 이미지를 \(N\)개의 Filter로 Convolution한 결과로
가로 길이가 \(x\), 세로 길이가 \(y\) 인 Feature Map 매트릭스가 \(N\)개 있다.
Channel & Kernel 섹션에서, 1장의 컬러 이미지가 3 Channel로 구성돼 있을 경우, 우리는 3개의 Kernel을 가진 1개 Filter를 사용해서 Convolution을 했다.
이 경우도 마찬가지다. Conv1 Layer는 \(N\)개의 Channel을 가진 것이라 볼수 있으므로
\(N\)개의 Kernel을 가진 1개 Filter로 Convolution을 수행하고 그 결과로 1개의 Feature Map을 얻을 수 있다.
또한 \(N\) 만큼의 두께를 가진 Conv1 Layer에서 그보다 더 두꺼운 Conv2 Layer를 만들기 위해서는
아래처럼 \(N\)개의 Kernel을 가진 Filter를 \(M\)개 만큼 사용하면 된다.
그러면 각 Filter 마다 1개의 Feature Map을 생성할 것이므로 총 \(M\)개의 Feature Map을 얻을 수 있다.
이처럼 Convolution 결과에 다시금 Convolution을 수행하는 것은 추출한 모양 정보에서 또다시 모양을 추출하는 작업이므로 추출 깊이가 심화됨에 따라 이미지 속 Object의 특징적인 모양을 감지하는 능력이 향상 될 것이라 예상 할 수 있다.
Pooling
CNN에서 Pooling이란 Convolution 연산 결과를 축소시키는 작업이다.
Pooling을 하면 아래와 같이 Feature Map의 가로 \(x\), 세로 \(y\)의 길이가 줄어든다.
그리고 그만큼 정보 손실이 발생 할 수 있다.
Max Pooling
Pooling에도 여러가지 방법이 있는데 그중 일반적인 방법은 Max-Pooling이다. 이 방법은 아래 애니메이션 처럼 Feature Map의 사이즈보다 작은 영역을 잡아서 Feature Map을 스캔하는데, 그때마다 영역 내 결과 중 가장 큰 값 하나만 뽑아 내는 방식이다.
그러면 영역 크기 2x2 4칸 중 1칸만 뽑아 내므로 그 결과의 크기는 원래의 Feature Map 보다 작다.
이 과정을 \(N\)개의 Feature Map 각각에 대해 수행하면 가로x세로 크기가 원래의 Feature Map보다 작고(\(x'\)x\(y'\)), 개수는 \(N\)개로 동일한 Pooling 된 Feature Map을 얻을 수 있다.
위 그림에서 영역은 이동할 때 1 stride 하고 있는데, 이는 개발자 의도에 따라 조절 가능하다.
Max Pooling은 Convolution 연산 결과에서 그 영향이 가장 큰 하나만 사용하는 효과를 낸다. 따라서 Convolution으로 이미지 고유의 독특한 모양 특성을 추출했다면 그 정보를 극대화시켜서 다음 Layer로 전달하고 CNN 모델의 성능을 향상 시킬 수 있다.
또한 해상도를 낮추듯 연산량, 학습량을 줄여줄 수 있다. 학습량이 줄어들면 모델 성능이 떨어질 수도 있지만 오히려 빠르고 정확한 학습이 가능할 수도 있다. 그러므로 그 적정선에 잘 위치하도록 Pooling의 종류나 영역의 크기, stride 정도 등 Hyper Parameter를 조절하는 것이 중요하다.
그밖에 Min-Pooling, Average Pooling 등 다른 방법들이 있고 머신의 목적에 따라 효율이 좋은 방법이 달라진다.
나머지 연산들
위에서 보인 CNN 구조에서 설명하지 않고 남은것은 Relu와 Fully Connected Layer, Classification이다.
이런 요소들은 CNN 만의 특별한 요소가 아니며 Deep Learning 분야에서 널리 쓰이는 기술들이므로 이 포스트에서는 다루지 않는다.
CNN의 발전
CNN 알고리즘은 개선을 거듭하면서 LeNet, AlexNet, GoogleNet(Inception), VGGNet, ResNet 등 다양한 구조의 모델로 개발되고 있으며 특정 분야에서 인간과 비슷하거나 상회하는 성능을 내고 있다.
아래 그림은 ILSVRC2012-2014 시절의 ImageNet 데이터를 기준으로 실험한 논문의 내용이다. 10년 전부터 Image Classification 분야에서 CNN 모델의 위상을 보여준다.
Top 5 Accuracy를 측정한 결과인데 주의할 점은 논문의 벤치마크 결과는 논문 마다 시간 차이, 미세한 조정 차이 등으로 실험 결과가 조금씩 다를 수 있다.
Performance Comparison of CNN Models
위 차트의 x축은 연산량, y축은 Image Classification에서 1 Top Accuracy, 원의 크기는 Parameter의 개수이며 차트 위에 여러가지 CNN Model들을 비교하고 있다.
이러한 발전된 형태의 CNN에 대해서는 추후에 다루도록 하겠다.
CNN의 문제점
CNN은 문제점이자 취약점이 있는데 원본 이미지에 흰색(RGB 255,255,255)점을 찍거나 Noise를 섞는 방식으로 이미지를 왜곡한 후 CNN을 수행하면 그러한 왜곡이 오히려 내부적으로 극대화 되고 모델 성능을 심각하게 떨어트릴 수 있다. 이에 관련한 연구들도 많이 진행중인데 자세히 보진 않았지만 Convolution과 Max-Pooling 기법에서 오는것으로 예상된다.
아래 그림은 판다 이미지에 Noise를 섞는 것을 보여준다. Noise가 섞인 판다는 인간이 볼때는 차이를 느낄수 없다. 하지만 CNN 알고리즘은 Noise에 큰 방해를 받고 전혀 다른 Image Classification 결과를 반환한다.
컴퓨터 생태계에 해커가 있듯, 누군가는 이런 취약점을 노려 고의로 모델을 방해하는 문제(Adversarial Attack)를 일으킬 수도 있다. 만약 자율 자동차에 CNN 알고리즘을 도입했는데, 누군가가 교통 표지판에 테이프를 몇개 붙여서 이미지 인식을 교란하면 어쩌면 인명 피해를 일으킬지도 모른다.
- https://en.wikipedia.org/wiki/Convolutional_neural_network
- https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215#:~:text=A%20%E2%80%9CKernel%E2%80%9D%20refers%20to%20a,is%20a%20collection%20of%20kernels.
- http://taewan.kim/post/cnn/
- https://blog.naver.com/laonple/220830178487
Leave a comment